
 zhayujie
2 år sedan
zhayujie
2 år sedan
11 ändrade filer med 107 tillägg och 43 borttagningar
+ 41
- 27
README.md
Visa fil
| @@ -1,61 +1,61 @@ | |||||
| # 简介 | # 简介 | ||||
| 本项目是基于ChatGPT模型实现的微信聊天机器人,通过[revChatGPT](https://github.com/acheong08/ChatGPT) 访问 ChatGPT接口,使用 [itchat](https://github.com/littlecodersh/ItChat) 实现微信消息的接收和发送。已实现的功能如下: | |||||
| 本项目是基于ChatGPT模型实现的微信聊天机器人,通过 [OpenAI](https://github.com/acheong08/ChatGPT) 访提供的API,使用 [itchat](https://github.com/littlecodersh/ItChat) 实现微信消息的接收和发送。已实现的功能如下: | |||||
| - [x] **基础功能:** 接收私聊及群组中的微信消息,使用ChatGPT生成回复内容,完成自动回复 | - [x] **基础功能:** 接收私聊及群组中的微信消息,使用ChatGPT生成回复内容,完成自动回复 | ||||
| - [x] **规则定制化:** 支持私聊中按指定规则触发自动回复,支持对群组设置自动回复白名单 | - [x] **规则定制化:** 支持私聊中按指定规则触发自动回复,支持对群组设置自动回复白名单 | ||||
| - [x] **会话上下文:** 支持用户维度的上下文保存和过期清理 | |||||
| - [x] **Session刷新:** 支持ChatGPT session的定时刷新保鲜 | |||||
| - [x] **多账号:** 支持多微信账号同时运行 | - [x] **多账号:** 支持多微信账号同时运行 | ||||
| - [ ] **会话上下文:** 支持用户维度的上下文记忆 | |||||
| # 更新 | |||||
| > **2022.12.17:** 原来的方案是从 [ChatGPT页面](https://chat.openai.com/chat) 获取session_token,使用 [revChatGPT](https://github.com/acheong08/ChatGPT) 直接访问web接口,但随着ChatGPT接入Cloudflare人机验证,这一方案难以在服务器顺利运行。 所以目前使用的方案是调用 OpenAI 官方提供的 [API](https://beta.openai.com/docs/api-reference/introduction),劣势是暂不支持有上下文记忆的对话、且回复内容的智能性上相比ChatGPT稍差一些,优势是稳定性和响应速度较好。 | |||||
| # 快速开始 | # 快速开始 | ||||
| ## 准备 | ## 准备 | ||||
| ### 1.网页版微信 | |||||
| ### 1.网页版微信 | |||||
| 本方案中实现微信消息的收发依赖了网页版微信的登录,可以尝试登录 <https://wx.qq.com/>,如果能够成功登录就可以开始后面的步骤了。 | 本方案中实现微信消息的收发依赖了网页版微信的登录,可以尝试登录 <https://wx.qq.com/>,如果能够成功登录就可以开始后面的步骤了。 | ||||
| ### 2.运行环境 | |||||
| ### 2. OpenAI账号注册 | |||||
| 前往 [OpenAI注册页面](https://beta.openai.com/signup) 创建账号,参考这篇 [博客](https://www.cnblogs.com/damugua/p/16969508.html) 可以通过虚拟手机号来接收验证码。创建完账号则前往 [API管理页面](https://beta.openai.com/account/api-keys) 创建一个 API Key 并保存下来,后面需要在项目中配置这个key。 | |||||
| > 项目中使用的对话模型是 davinci,计费方式是每1k字 (包含请求和回复) 消耗 $0.02,账号创建有免费的 $18 额度,使用完可以更换邮箱重新注册。 | |||||
| 操作系统支持 Linux、MacOS、Windows,并需安装 `Python3.6` 及以上版本。推荐使用Linux服务器,可以托管在后台长期运行。 | |||||
| ### 3.项目安装 | |||||
| ### 3.运行环境 | |||||
| 克隆本项目代码: | |||||
| 支持运行在 Linux、MacOS、Windows 操作系统上,需安装 `Python3.6` 及以上版本。推荐使用Linux服务器,可以托管在后台长期运行。 | |||||
| 克隆项目代码: | |||||
| ```bash | ```bash | ||||
| https://github.com/zhayujie/chatgpt-on-wechat | https://github.com/zhayujie/chatgpt-on-wechat | ||||
| ``` | ``` | ||||
| 安装所需依赖: | |||||
| 安装所需核心依赖: | |||||
| ```bash | ```bash | ||||
| pip3 install revChatGPT | |||||
| pip3 install itchat | pip3 install itchat | ||||
| pip3 install openai | |||||
| ``` | ``` | ||||
| ## 配置 | ## 配置 | ||||
| 配置文件在根目录的 `config.json` 中,示例文件及各配置项解析如下: (TODO) | |||||
| 配置文件在根目录的 `config.json` 中,示例文件及各配置项含义如下: | |||||
| ```bash | ```bash | ||||
| { | { | ||||
| "session_token": "YOUR SESSION TOKEN", # 从页面获取的token | |||||
| "single_chat_prefix": ["bot", "@bot"], # 私聊触发自动回复的前缀 | |||||
| "group_chat_prefix": ["@bot"], # 群聊触发自动回复的前缀 | |||||
| "group_name_white_list": ["群名称1", "群名称2"] # 开启自动回复的群名称 | |||||
| "open_ai_api_key": "${YOUR API KEY}$" # 上面在创建的 API KEY | |||||
| "single_chat_prefix": ["bot", "@bot"], # 私聊时文本需要包含该前缀才能触发机器人回复 | |||||
| "single_chat_reply_prefix": "[bot] ", # 私聊时自动回复的前缀,用于区分真人 | |||||
| "group_chat_prefix": ["@bot"], # 群聊时包含该前缀则会触发机器人回复 | |||||
| "group_name_white_list": ["ChatGPT测试群", "ChatGPT测试群2"] # 开启自动回复的群名称列表 | |||||
| } | } | ||||
| ``` | ``` | ||||
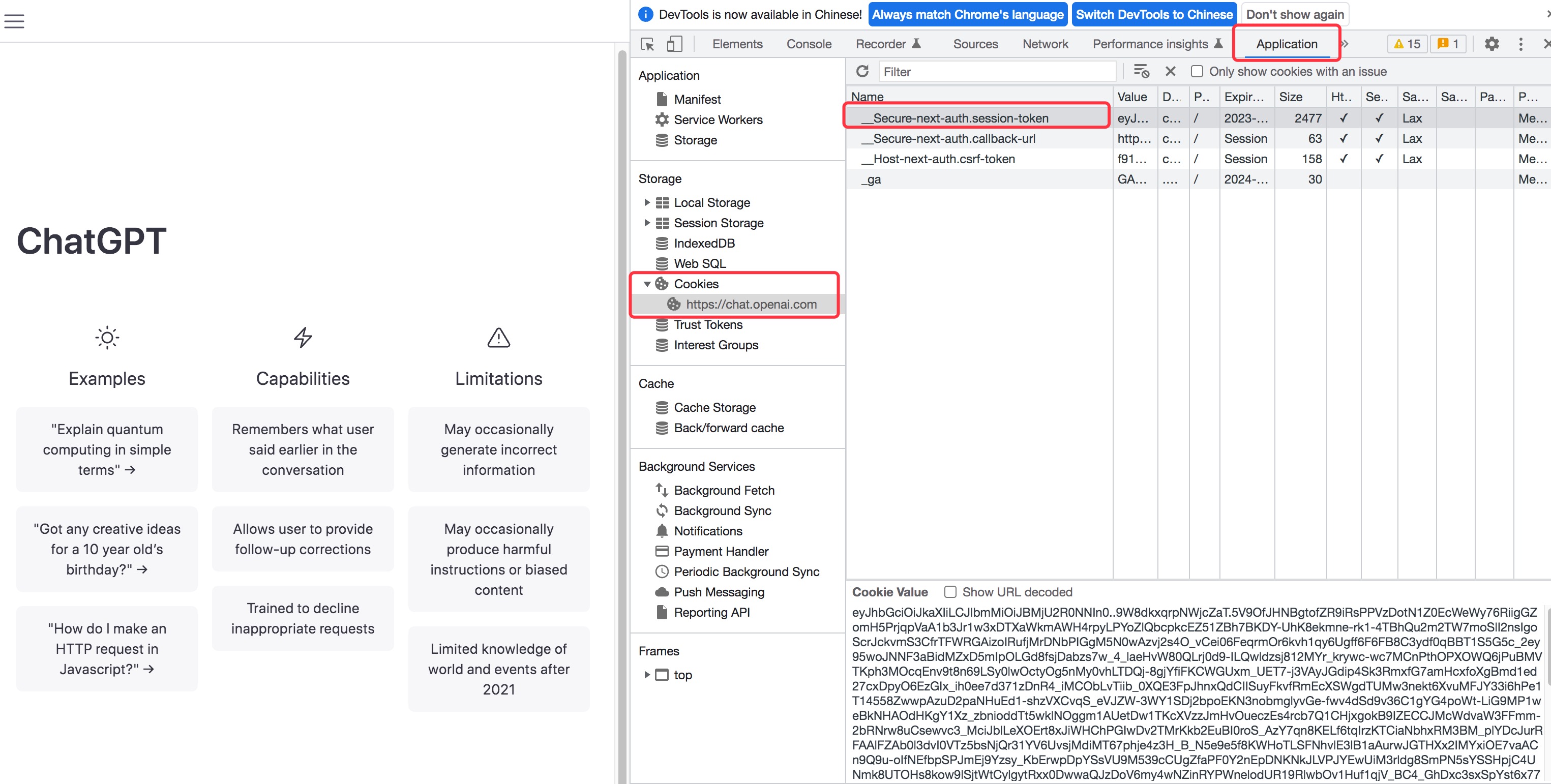
| 其中 session_token 需要在openAI网页端获取: | |||||
| - 打开 <https://chat.openai.com/chat> 并登录,可使用测试账号 (lgfo353p@linshiyouxiang.net, 密码yy123123),账号来源为该[文章](https://www.bilibili.com/read/cv20257021) | |||||
| - F12 进入开发者控制台 | |||||
| - 选择Application -> Cookies,将 session-token 中的值填入配置中 | |||||
|  | |||||
| 关于OpenAI对话接口的参数配置,可以参考 [接口文档](https://beta.openai.com/docs/api-reference/completions) 直接在代码 `bot\openai\open_ai_bot.py` 中进行调整。 | |||||
| ## 运行 | ## 运行 | ||||
| @@ -71,8 +71,22 @@ python3 app.py | |||||
| 2.如果是服务器部署,则使用nohup在后台运行: | 2.如果是服务器部署,则使用nohup在后台运行: | ||||
| ``` | ``` | ||||
| nohup python3 app.py & | |||||
| nohup python3 app.py & tail -f nohup.out | |||||
| ``` | ``` | ||||
| 同样在扫码后程序即可运行于后台。 | |||||
| ## 使用 | ## 使用 | ||||
| ### 个人聊天 | |||||
|  | |||||
| 默认配置中,个人聊天会以 "bot" 或 "@bot" 为开头的内容触发机器人,对应配置中的 `single_chat_prefix`;机器人回复的内容会以 "[bot]" 作为前缀, 以区分真人,对应的配置为 `single_chat_reply_prefix`。 | |||||
| ### 群组聊天 | |||||
|  | |||||
| 群名称需要配置在 `group_name_white_list ` 中才能开启群聊自动回复,默认只要被@就会触发机器人自动回复,另外群聊天中只要检测到以 "@bot" 开头的内容,同样会自动回复,这对应配置 `group_chat_prefix`。 | |||||
+ 1
- 0
bot/baidu/baidu_unit_bot.py
Visa fil
| @@ -4,6 +4,7 @@ import requests | |||||
| from bot.bot import Bot | from bot.bot import Bot | ||||
| # Baidu Unit对话接口 (可用, 但能力较弱) | |||||
| class BaiduUnitBot(Bot): | class BaiduUnitBot(Bot): | ||||
| def reply(self, query, context=None): | def reply(self, query, context=None): | ||||
| token = self.get_token() | token = self.get_token() | ||||
+ 10
- 3
bot/bot_factory.py
Visa fil
| @@ -2,9 +2,6 @@ | |||||
| channel factory | channel factory | ||||
| """ | """ | ||||
| from bot.baidu.baidu_unit_bot import BaiduUnitBot | |||||
| from bot.chatgpt.chat_gpt_bot import ChatGPTBot | |||||
| def create_bot(bot_type): | def create_bot(bot_type): | ||||
| """ | """ | ||||
| @@ -13,7 +10,17 @@ def create_bot(bot_type): | |||||
| :return: channel instance | :return: channel instance | ||||
| """ | """ | ||||
| if bot_type == 'baidu': | if bot_type == 'baidu': | ||||
| # Baidu Unit对话接口 | |||||
| from bot.baidu.baidu_unit_bot import BaiduUnitBot | |||||
| return BaiduUnitBot() | return BaiduUnitBot() | ||||
| elif bot_type == 'chatGPT': | elif bot_type == 'chatGPT': | ||||
| # ChatGPT 网页端web接口 | |||||
| from bot.chatgpt.chat_gpt_bot import ChatGPTBot | |||||
| return ChatGPTBot() | return ChatGPTBot() | ||||
| elif bot_type == 'openAI': | |||||
| # OpenAI 官方对话模型API | |||||
| from bot.openai.open_ai_bot import OpenAIBot | |||||
| return OpenAIBot() | |||||
| raise RuntimeError | raise RuntimeError | ||||
+ 2
- 0
bot/chatgpt/chat_gpt_bot.py
Visa fil
| @@ -7,6 +7,8 @@ from config import conf | |||||
| user_session = dict() | user_session = dict() | ||||
| last_session_refresh = time.time() | last_session_refresh = time.time() | ||||
| # ChatGPT web接口 (暂时不可用) | |||||
| class ChatGPTBot(Bot): | class ChatGPTBot(Bot): | ||||
| def __init__(self): | def __init__(self): | ||||
| config = { | config = { | ||||
+ 30
- 0
bot/openai/open_ai_bot.py
Visa fil
| @@ -0,0 +1,30 @@ | |||||
| from bot.bot import Bot | |||||
| from config import conf | |||||
| from common.log import logger | |||||
| import openai | |||||
| # OpenAI对话模型API (可用) | |||||
| class OpenAIBot(Bot): | |||||
| def __init__(self): | |||||
| openai.api_key = conf().get('open_ai_api_key') | |||||
| def reply(self, query, context=None): | |||||
| logger.info("[OPEN_AI] query={}".format(query)) | |||||
| try: | |||||
| response = openai.Completion.create( | |||||
| model="text-davinci-003", #对话模型的名称 | |||||
| prompt=query, | |||||
| temperature=0.9, #值在[0,1]之间,越大表示回复越具有不确定性 | |||||
| max_tokens=1200, #回复最大的字符数 | |||||
| top_p=1, | |||||
| frequency_penalty=0.0, #[-2,2]之间,该值越大则更倾向于产生不同的内容 | |||||
| presence_penalty=0.2, #[-2,2]之间,该值越大则更倾向于产生不同的内容 | |||||
| stop=["#"] | |||||
| ) | |||||
| res_content = response.choices[0]["text"].strip() | |||||
| except Exception as e: | |||||
| logger.error(e) | |||||
| return None | |||||
| logger.info("[OPEN_AI] reply={}".format(res_content)) | |||||
| return res_content | |||||
+ 1
- 1
bridge/bridge.py
Visa fil
| @@ -6,4 +6,4 @@ class Bridge(object): | |||||
| pass | pass | ||||
| def fetch_reply_content(self, query, context): | def fetch_reply_content(self, query, context): | ||||
| return bot_factory.create_bot("chatGPT").reply(query, context) | |||||
| return bot_factory.create_bot("openAI").reply(query, context) | |||||
+ 19
- 10
channel/wechat/wechat_channel.py
Visa fil
| @@ -36,20 +36,25 @@ class WechatChannel(Channel): | |||||
| def handle(self, msg): | def handle(self, msg): | ||||
| logger.info("[WX]receive msg: " + json.dumps(msg, ensure_ascii=False)) | logger.info("[WX]receive msg: " + json.dumps(msg, ensure_ascii=False)) | ||||
| from_user_id = msg['FromUserName'] | from_user_id = msg['FromUserName'] | ||||
| to_user_id = msg['ToUserName'] | |||||
| other_user_id = msg['User']['UserName'] | other_user_id = msg['User']['UserName'] | ||||
| content = msg['Text'] | content = msg['Text'] | ||||
| if from_user_id == other_user_id and \ | if from_user_id == other_user_id and \ | ||||
| self.check_prefix(content, conf().get('group_chat_prefix')): | |||||
| self.check_prefix(content, conf().get('single_chat_prefix')): | |||||
| str_list = content.split('bot', 1) | str_list = content.split('bot', 1) | ||||
| if len(str_list) == 2: | if len(str_list) == 2: | ||||
| content = str_list[1].strip() | content = str_list[1].strip() | ||||
| thead_pool.submit(self._do_send, content, from_user_id) | thead_pool.submit(self._do_send, content, from_user_id) | ||||
| elif to_user_id == other_user_id and \ | |||||
| self.check_prefix(content, conf().get('single_chat_prefix')): | |||||
| str_list = content.split('bot', 1) | |||||
| if len(str_list) == 2: | |||||
| content = str_list[1].strip() | |||||
| thead_pool.submit(self._do_send, content, to_user_id) | |||||
| def handle_group(self, msg): | def handle_group(self, msg): | ||||
| logger.info("[WX]receive group msg: " + json.dumps(msg, ensure_ascii=False)) | logger.info("[WX]receive group msg: " + json.dumps(msg, ensure_ascii=False)) | ||||
| group_id = msg['User']['UserName'] | |||||
| group_name = msg['User'].get('NickName', None) | group_name = msg['User'].get('NickName', None) | ||||
| if not group_name: | if not group_name: | ||||
| return "" | return "" | ||||
| @@ -72,18 +77,22 @@ class WechatChannel(Channel): | |||||
| logger.info('[WX] sendMsg={}, receiver={}'.format(msg, receiver)) | logger.info('[WX] sendMsg={}, receiver={}'.format(msg, receiver)) | ||||
| itchat.send(msg, toUserName=receiver) | itchat.send(msg, toUserName=receiver) | ||||
| def _do_send(self, send_msg, reply_user_id): | |||||
| def _do_send(self, query, reply_user_id): | |||||
| if not query: | |||||
| return | |||||
| context = dict() | context = dict() | ||||
| context['from_user_id'] = reply_user_id | context['from_user_id'] = reply_user_id | ||||
| content = super().build_reply_content(send_msg, context) | |||||
| if content: | |||||
| self.send("[bot] " + content, reply_user_id) | |||||
| reply_text = super().build_reply_content(query, context).strip() | |||||
| if reply_text: | |||||
| self.send(conf().get("single_chat_reply_prefix") + reply_text, reply_user_id) | |||||
| def _do_send_group(self, content, msg): | |||||
| def _do_send_group(self, query, msg): | |||||
| if not query: | |||||
| return | |||||
| context = dict() | context = dict() | ||||
| context['from_user_id'] = msg['ActualUserName'] | context['from_user_id'] = msg['ActualUserName'] | ||||
| reply_text = super().build_reply_content(content, context) | |||||
| reply_text = '@' + msg['ActualNickName'] + ' ' + reply_text | |||||
| reply_text = super().build_reply_content(query, context) | |||||
| reply_text = '@' + msg['ActualNickName'] + ' ' + reply_text.strip() | |||||
| if reply_text: | if reply_text: | ||||
| self.send(reply_text, msg['User']['UserName']) | self.send(reply_text, msg['User']['UserName']) | ||||
+ 3
- 2
config.json
Visa fil
| @@ -1,6 +1,7 @@ | |||||
| { | { | ||||
| "session_token": "eyJhbGciOiJkaXIiLCJlbmMiOiJBMjU2R0NNIn0..yUEdyIPaNgrKerHa.hQfnBM6Ry2npNvakpj1TL_4wr7fuMeLMWOmy-yOSzJxJw7DNyq5vwKeZBwOzthFBIuSu_CpHvYCK_SvRy2RW0gtjPh1XZMxoXejzwJ8VJaVrj3BjarIJdMKRaIHrFwYlRj6fdWa_nGWeueGf1EDE71aSHf4La-4YjoEX8Ou68XHXEsOYQqMuk06u8Wa_aRq5UAj3Clc99dEw3iHU7xvf8lMmB3T1G1LMaubH21niQj-76pUzlf1Kq278Yl8Q6fOGD_CA7mCvnA1LGYzo7u0P5A8dd-p7K3Oqbxw3Gn2TMyEkzZ2q_rTqSJwnbRG87SEYp5Y6HzYyfNoqM_Ew3OGQqk9PHbv8CjKN6sR53UMNRJeFxkW2owCsR0eCvc8kL-tc5RyHWF3zWVmlOxmzDaHZo_XlA0fgEpjlMZS1ClHCBT6_ZoQRvKan0dkFfhJEdp35aK_v9DLXs46Sfs2rqfN0Fdr698gv0UbGsLdeR00W7M9qMsvXoFDBW3-GnIqsxjjepDPlv4RInMKfSeVdISp4VPWW-GjGyzCB1ooWiyZybaGul1FsdXVSibMq6qsiGUQNr08uf_In3NUPFCKNxJ2iR6A_5-TEiIIjcK6ywbI87L13PFT3oCCXiFxRPjp4f1nUUTGxLcetGzYC_eYmQD004R5M5u1epQdWen4Of1Fzn7D0sOWibSHcl_J9xSxzzVt__b9NVDWieoaGYCO3MJCDVmucfFZ1UFPhIRwsr3nUnom8mnXJocDDSPlb0EWfZhCrMgjhPt7Iqcjg-uNB9QYZNjtHASAcQlUYx5GfP6IZs47UqqLPRlzUISsc65CPyQF6sFgwPO1GNy5Q7QcCUQreMmJdBUyYEUnrKCurZkfRWx2eEJ_1efnnprtUc_Upniar-5PJxAfsZ0Mw4QRweIriRB2CW7L24yZsLR7Q8xzm0vj4KeXeuZ7ZlJJw5f65xndTNwII0jS1-VriBsnKs1SDXJc3WEiviifG8Lx-IjirXoH8Q7RtcqPpRURJApu1aIaWtvSEw5mCGjynuINufN_GEu2r71i231_58IYSK9fBpmRKCkHmTZWkjJmiyhFaG2aYI8Z5UwXEUhOZoijb10ZGgcyW6cnSzuthWfa5VzcYFOa35tE69_xZ8W2A6YKuJeJlW01oXirYxtBazyG2o3dpg-mD_BD7hgU4_ONU8SBXubtbxtCzWqNzIg5F0d0e2pc5aNaDJH3yzK5X1y1nlBZe59l3vCmpmvBfgWzI2Q1pbM_me-1g5-w6ju_waQLvR-DPuUOown_EbiCZ7Zd7BAszVlPMgAMWIJ3AljMceIj6ned8YFldZztM_RdvM1qW_KohVurd_bt3vvIBD_c7gttJzAohod61TYBtu5esXNr-sHQNYfapPp8U8J6KZjJFJVEPdrNYeGFewVFVsgRCx_WfaEyIUTaoC9d_ZTDX_nFn_GJceUANqsJYB_FSbzz7aZLj2WKGK8WKw6ujkSMOrLpspt0meqohTWcV68aIMNDhLdOGS7R53vnTUoyrfGLi2HH9QyF5sjjy_YFz1Z9B1Pcv38c9XKBxHUCMNS9ws6IZlIMaA9z8F5_2s-LSKR88Atnb82gQy-BsRdffTI1IhnLLPeisPv_dVOChCdEVHmTMKDvkiYp9GobHW9V3WBm48K2mYDjR6eW459uJP1TVjGP00-O0FZDHTcBZ9L-pq93EbdhYv1VdT-S8UHWy_zoksV-D-iOmc8DKvEHU3CJcUlEf63vcRuBRzfJdeqvw2E4J5j9tt2tkAO814kng2fZaob8XUmjF3QKevYvY8NKAevp6cpoT7DIDZttT6mEkUy1pW02thh3FMqr_EfsCI5pR84BQCr-LIRDzhudnOxHxXOJXE_zuEt1QNNSAH0eqxA6Mx7N5p3WU7dU0ULGPMtEEXz1IwiGAJ21z8Z77EOrL3vOWUnq3Y1sAPD9PBzaPC8_wezBIXQqI6Ufa6D38xPdZnkoaxMd3PRFu91s9qMoYO4OZ1WfjbQJi51T4M76y1K73eBLGwVgWRguEs8Yqr2F-ctZ-BiSEa2RfOwYcmT5uRbFzZnQCtj32JTNMSIFGQ5It5bR0nPh5BK6LjK2_kbQny6dZ9d_KrBcl15REEKM9XhZOSGWRRwAmf_4iVsy6ceqXMuYMbEGL7xnw6tmBWzuuN21_1RnxY8JS8CtzjPC4LAIRgN7VE4M6LbEcQJiaw9hVsUzLueoP-CCtjBeqQ1ylsaz6C4rOpDISATG-jAQ66FE9P0YHXQXOAip4Bf7KO-IvSvZF_dKv2_RMdAE53dlpup5oCWqPk8qAVNgZXIT6LN8MiqRDVfObQDa-uElVtX8ll7ItOUXRoXUJfxabE6oW.bDrh_KN_-hbGsWTk_0z35g", | |||||
| "open_ai_api_key": "${YOUR API KEY}$", | |||||
| "single_chat_prefix": ["bot", "@bot"], | "single_chat_prefix": ["bot", "@bot"], | ||||
| "single_chat_reply_prefix": "[bot] ", | |||||
| "group_chat_prefix": ["@bot"], | "group_chat_prefix": ["@bot"], | ||||
| "group_name_white_list": ["群名称1", "群名称2"] | |||||
| "group_name_white_list": ["ChatGPT测试群", "ChatGPT测试群2"] | |||||
| } | } | ||||
Binär
docs/images/chatgpt-token.png
Visa fil
{kind=link}
| Before | After |
|---|---|
|
|
| Width: 3050 | Height: 1542 | Size: 709KB |
Binär
docs/images/group-chat-sample.jpg
Visa fil
{kind=link}
| Before | After |
|---|---|

|
|
| Width: 1652 | Height: 1288 | Size: 326KB |
Binär
docs/images/single-chat-sample.jpg
Visa fil
{kind=link}
| Before | After |
|---|---|

|
|
| Width: 1570 | Height: 1210 | Size: 186KB |
Laddar…