
14KB
简介
ChatGPT近期以强大的对话和信息整合能力风靡全网,可以写代码、改论文、讲故事,几乎无所不能,这让人不禁有个大胆的想法,能否用他的对话模型把我们的微信打造成一个智能机器人,可以在与好友对话中给出意想不到的回应,而且再也不用担心女朋友影响我们
打游戏工作了。
基于ChatGPT的微信聊天机器人,通过 ChatGPT 接口生成对话内容,使用 itchat 实现微信消息的接收和自动回复。已实现的特性如下:
- 文本对话: 接收私聊及群组中的微信消息,使用ChatGPT生成回复内容,完成自动回复
- 规则定制化: 支持私聊中按指定规则触发自动回复,支持对群组设置自动回复白名单
- 多账号: 支持多微信账号同时运行
- 图片生成: 支持根据描述生成图片,并自动发送至个人聊天或群聊
- 上下文记忆:支持多轮对话记忆,且为每个好友维护独立的上下会话
- 语音识别: 支持接收和处理语音消息,通过文字或语音回复
更新日志
2023.03.25: 支持插件化开发,目前已实现 多角色切换、文字冒险游戏、管理员指令、Stable Diffusion等插件,使用参考 #578。(contributed by @lanvent in #565)
2023.03.09: 基于
whisper API实现对微信语音消息的解析和回复,添加配置项"speech_recognition":true即可启用,使用参考 #415。(contributed by wanggang1987 in #385)2023.03.02: 接入ChatGPT API (gpt-3.5-turbo),默认使用该模型进行对话,需升级openai依赖 (
pip3 install --upgrade openai)。网络问题参考 #3512023.02.09: 扫码登录存在封号风险,请谨慎使用,参考#58
2023.02.05: 在openai官方接口方案中 (GPT-3模型) 实现上下文对话
2022.12.18: 支持根据描述生成图片并发送,openai版本需大于0.25.0
2022.12.17: 原来的方案是从 ChatGPT页面 获取session_token,使用 revChatGPT 直接访问web接口,但随着ChatGPT接入Cloudflare人机验证,这一方案难以在服务器顺利运行。 所以目前使用的方案是调用 OpenAI 官方提供的 API,回复质量上基本接近于ChatGPT的内容,劣势是暂不支持有上下文记忆的对话,优势是稳定性和响应速度较好。
使用效果
个人聊天

群组聊天

图片生成
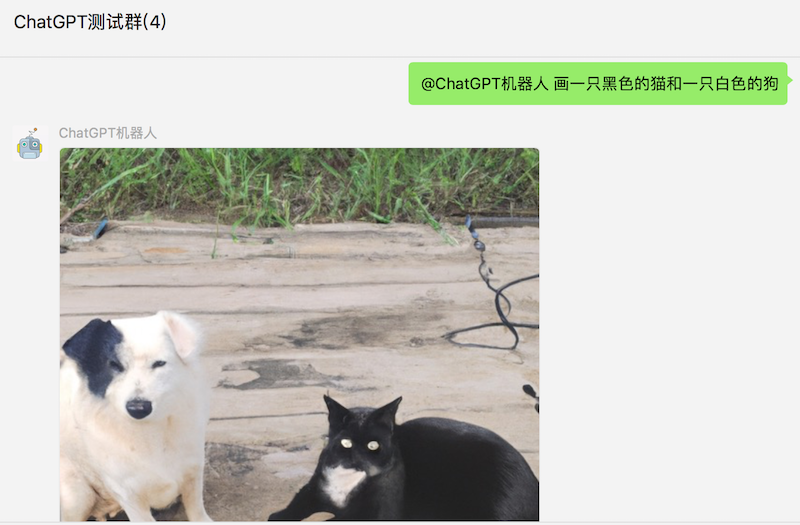
快速开始
准备
1. OpenAI账号注册
前往 OpenAI注册页面 创建账号,参考这篇 教程 可以通过虚拟手机号来接收验证码。创建完账号则前往 API管理页面 创建一个 API Key 并保存下来,后面需要在项目中配置这个key。
项目中使用的对话模型是 davinci,计费方式是约每 750 字 (包含请求和回复) 消耗 $0.02,图片生成是每张消耗 $0.016,账号创建有免费的 $18 额度 (更新3.25: 最新注册的已经无免费额度了),使用完可以更换邮箱重新注册。
1.1 ChapGPT service On Azure
一种替换以上的方法是使用Azure推出的ChatGPT service。它host在公有云Azure上,因此不需要VPN就可以直接访问。不过目前仍然处于preview阶段。新用户可以通过Try Azure for free来薅一段时间的羊毛
2.运行环境
支持 Linux、MacOS、Windows 系统(可在Linux服务器上长期运行),同时需安装 Python。
建议Python版本在 3.7.1~3.9.X 之间,3.10及以上版本在 MacOS 可用,其他系统上不确定能否正常运行。
(1) 克隆项目代码:
git clone https://github.com/zhayujie/chatgpt-on-wechat
cd chatgpt-on-wechat/
(2) 安装核心依赖 (必选):
pip3 install itchat-uos==1.5.0.dev0
pip3 install --upgrade openai
注:itchat-uos使用指定版本1.5.0.dev0,openai使用最新版本,需高于0.27.0。
(3) 拓展依赖 (可选):
语音识别及语音回复相关依赖:#415。 让会话token数量的计算更加精准:
pip3 install --upgrade tiktoken
配置
配置文件的模板在根目录的config-template.json中,需复制该模板创建最终生效的 config.json 文件:
cp config-template.json config.json
然后在config.json中填入配置,以下是对默认配置的说明,可根据需要进行自定义修改:
# config.json文件内容示例
{
"open_ai_api_key": "YOUR API KEY", # 填入上面创建的 OpenAI API KEY
"model": "gpt-3.5-turbo", # 模型名称。当use_azure_chatgpt为true时,其名称为Azure上model deployment名称
"proxy": "127.0.0.1:7890", # 代理客户端的ip和端口
"single_chat_prefix": ["bot", "@bot"], # 私聊时文本需要包含该前缀才能触发机器人回复
"single_chat_reply_prefix": "[bot] ", # 私聊时自动回复的前缀,用于区分真人
"group_chat_prefix": ["@bot"], # 群聊时包含该前缀则会触发机器人回复
"group_name_white_list": ["ChatGPT测试群", "ChatGPT测试群2"], # 开启自动回复的群名称列表
"group_chat_in_one_session": ["ChatGPT测试群"], # 支持会话上下文共享的群名称
"image_create_prefix": ["画", "看", "找"], # 开启图片回复的前缀
"conversation_max_tokens": 1000, # 支持上下文记忆的最多字符数
"speech_recognition": false, # 是否开启语音识别
"group_speech_recognition": false, # 是否开启群组语音识别 (目前仅支持wechaty)
"use_azure_chatgpt": false, # 是否使用Azure ChatGPT service代替openai ChatGPT service. 当设置为true时需要设置 open_ai_api_base,如 https://xxx.openai.azure.com/
"character_desc": "你是ChatGPT, 一个由OpenAI训练的大型语言模型, 你旨在回答并解决人们的任何问题,并且可以使用多种语言与人交流。", # 人格描述,
}
配置说明:
1.个人聊天
- 个人聊天中,需要以 “bot”或”@bot” 为开头的内容触发机器人,对应配置项
single_chat_prefix(如果不需要以前缀触发可以填写"single_chat_prefix": [""]) - 机器人回复的内容会以 “[bot] ” 作为前缀, 以区分真人,对应的配置项为
single_chat_reply_prefix(如果不需要前缀可以填写"single_chat_reply_prefix": "")
2.群组聊天
- 群组聊天中,群名称需配置在
group_name_white_list中才能开启群聊自动回复。如果想对所有群聊生效,可以直接填写"group_name_white_list": ["ALL_GROUP"] - 默认只要被人 @ 就会触发机器人自动回复;另外群聊天中只要检测到以 “@bot” 开头的内容,同样会自动回复(方便自己触发),这对应配置项
group_chat_prefix - 可选配置:
group_name_keyword_white_list配置项支持模糊匹配群名称,group_chat_keyword配置项则支持模糊匹配群消息内容,用法与上述两个配置项相同。(Contributed by evolay) group_chat_in_one_session:使群聊共享一个会话上下文,配置["ALL_GROUP"]则作用于所有群聊
3.语音识别
- 添加
"speech_recognition": true将开启语音识别,默认使用openai的whisper模型识别为文字,同时以文字回复,该参数仅支持私聊 (注意由于语音消息无法匹配前缀,一旦开启将对所有语音自动回复); - 添加
"group_speech_recognition": true将开启群组语音识别,默认使用openai的whisper模型识别为文字,同时以文字回复,参数仅支持群聊 (可以匹配group_chat_prefix和group_chat_keyword,目前仅支持wechaty方案); - 添加
"voice_reply_voice": true将开启语音回复语音(同时作用于私聊和群聊),但是需要配置对应语音合成平台的key,由于itchat协议的限制,只能发送语音mp3文件,若使用wechaty则回复的是微信语音。
4.其他配置
model: 模型名称,目前支持gpt-3.5-turbo,text-davinci-003,gpt-4,gpt-4-32k(其中gpt-4 api暂未开放)temperature,frequency_penalty,presence_penalty: Chat API接口参数,详情参考OpenAI官方文档。proxy:由于目前openai接口国内无法访问,需配置代理客户端的地址,详情参考 #351- 对于图像生成,在满足个人或群组触发条件外,还需要额外的关键词前缀来触发,对应配置
image_create_prefix - 关于OpenAI对话及图片接口的参数配置(内容自由度、回复字数限制、图片大小等),可以参考 对话接口 和 图像接口 文档直接在 代码
bot/openai/open_ai_bot.py中进行调整。 conversation_max_tokens:表示能够记忆的上下文最大字数(一问一答为一组对话,如果累积的对话字数超出限制,就会优先移除最早的一组对话)rate_limit_chatgpt,rate_limit_dalle:每分钟最高问答速率、画图速率,超速后排队按序处理。clear_memory_commands: 对话内指令,主动清空前文记忆,字符串数组可自定义指令别名。hot_reload: 程序退出后,暂存微信扫码状态,默认关闭。character_desc配置中保存着你对机器人说的一段话,他会记住这段话并作为他的设定,你可以为他定制任何人格 (关于会话上下文的更多内容参考该 issue)
运行
1.本地运行
如果是开发机 本地运行,直接在项目根目录下执行:
python3 app.py
终端输出二维码后,使用微信进行扫码,当输出 “Start auto replying” 时表示自动回复程序已经成功运行了(注意:用于登录的微信需要在支付处已完成实名认证)。扫码登录后你的账号就成为机器人了,可以在微信手机端通过配置的关键词触发自动回复 (任意好友发送消息给你,或是自己发消息给好友),参考#142。
2.服务器部署
使用nohup命令在后台运行程序:
touch nohup.out # 首次运行需要新建日志文件
nohup python3 app.py & tail -f nohup.out # 在后台运行程序并通过日志输出二维码
扫码登录后程序即可运行于服务器后台,此时可通过 ctrl+c 关闭日志,不会影响后台程序的运行。使用 ps -ef | grep app.py | grep -v grep 命令可查看运行于后台的进程,如果想要重新启动程序可以先 kill 掉对应的进程。日志关闭后如果想要再次打开只需输入 tail -f nohup.out。此外,scripts 目录下有一键运行、关闭程序的脚本供使用。
注意: 如果 扫码后手机提示登录验证需要等待5s,而终端的二维码再次刷新并提示
Log in time out, reloading QR code,此时需参考此 issue 修改一行代码即可解决。多账号支持: 将 项目复制多份,分别启动程序,用不同账号扫码登录即可实现同时运行。
特殊指令: 用户向机器人发送 #清除记忆 即可清空该用户的上下文记忆。
3.Docker部署
参考文档 Docker部署 (Contributed by limccn)。
4. Railway部署
Use with Railway(PaaS, Free, Stable, ✅Recommended)
Railway offers $5 (500 hours) of runtime per month
- Click the Railway button to go to the Railway homepage
- Click the
Start New Projectbutton.- Click the
Deploy from Github repobutton.- Choose your repo (you can fork this repo firstly)
- Set environment variable to override settings in config-template.json, such as: model, open_ai_api_base, open_ai_api_key, use_azure_chatgpt etc.
常见问题
FAQs: https://github.com/zhayujie/chatgpt-on-wechat/wiki/FAQs
联系
欢迎提交PR、Issues,以及Star支持一下。程序运行遇到问题优先查看 常见问题列表 ,其次前往 Issues 中搜索,若无相似问题可创建Issue,或加微信 eijuyahz 交流。