
 JS00000
1 anno fa
JS00000
1 anno fa
17 ha cambiato i file con 253 aggiunte e 43 eliminazioni
+ 3
- 1
.gitignore
Vedi File
| @@ -13,6 +13,7 @@ plugins.json | |||||
| itchat.pkl | itchat.pkl | ||||
| *.log | *.log | ||||
| user_datas.pkl | user_datas.pkl | ||||
| chatgpt_tool_hub/ | |||||
| plugins/**/ | plugins/**/ | ||||
| !plugins/bdunit | !plugins/bdunit | ||||
| !plugins/dungeon | !plugins/dungeon | ||||
| @@ -22,4 +23,5 @@ plugins/**/ | |||||
| !plugins/banwords | !plugins/banwords | ||||
| !plugins/banwords/**/ | !plugins/banwords/**/ | ||||
| !plugins/hello | !plugins/hello | ||||
| !plugins/role | |||||
| !plugins/role | |||||
| !plugins/keyword | |||||
+ 1
- 1
bot/chatgpt/chat_gpt_bot.py
Vedi File
| @@ -142,7 +142,7 @@ class ChatGPTBot(Bot, OpenAIImage): | |||||
| logger.warn("[CHATGPT] RateLimitError: {}".format(e)) | logger.warn("[CHATGPT] RateLimitError: {}".format(e)) | ||||
| result["content"] = "提问太快啦,请休息一下再问我吧" | result["content"] = "提问太快啦,请休息一下再问我吧" | ||||
| if need_retry: | if need_retry: | ||||
| time.sleep(5) | |||||
| time.sleep(20) | |||||
| elif isinstance(e, openai.error.Timeout): | elif isinstance(e, openai.error.Timeout): | ||||
| logger.warn("[CHATGPT] Timeout: {}".format(e)) | logger.warn("[CHATGPT] Timeout: {}".format(e)) | ||||
| result["content"] = "我没有收到你的消息" | result["content"] = "我没有收到你的消息" | ||||
+ 1
- 1
bot/openai/open_ai_bot.py
Vedi File
| @@ -114,7 +114,7 @@ class OpenAIBot(Bot, OpenAIImage): | |||||
| logger.warn("[OPEN_AI] RateLimitError: {}".format(e)) | logger.warn("[OPEN_AI] RateLimitError: {}".format(e)) | ||||
| result["content"] = "提问太快啦,请休息一下再问我吧" | result["content"] = "提问太快啦,请休息一下再问我吧" | ||||
| if need_retry: | if need_retry: | ||||
| time.sleep(5) | |||||
| time.sleep(20) | |||||
| elif isinstance(e, openai.error.Timeout): | elif isinstance(e, openai.error.Timeout): | ||||
| logger.warn("[OPEN_AI] Timeout: {}".format(e)) | logger.warn("[OPEN_AI] Timeout: {}".format(e)) | ||||
| result["content"] = "我没有收到你的消息" | result["content"] = "我没有收到你的消息" | ||||
+ 2
- 0
bridge/context.py
Vedi File
| @@ -8,6 +8,8 @@ class ContextType(Enum): | |||||
| VOICE = 2 # 音频消息 | VOICE = 2 # 音频消息 | ||||
| IMAGE = 3 # 图片消息 | IMAGE = 3 # 图片消息 | ||||
| IMAGE_CREATE = 10 # 创建图片命令 | IMAGE_CREATE = 10 # 创建图片命令 | ||||
| JOIN_GROUP = 20 # 加入群聊 | |||||
| PATPAT = 21 # 拍了拍 | |||||
| def __str__(self): | def __str__(self): | ||||
| return self.name | return self.name | ||||
+ 22
- 9
channel/wechat/wechat_channel.py
Vedi File
| @@ -26,20 +26,25 @@ from lib.itchat.content import * | |||||
| from plugins import * | from plugins import * | ||||
| @itchat.msg_register([TEXT, VOICE, PICTURE]) | |||||
| @itchat.msg_register([TEXT, VOICE, PICTURE, NOTE]) | |||||
| def handler_single_msg(msg): | def handler_single_msg(msg): | ||||
| # logger.debug("handler_single_msg: {}".format(msg)) | |||||
| if msg["Type"] == PICTURE and msg["MsgType"] == 47: | |||||
| try: | |||||
| cmsg = WeChatMessage(msg, False) | |||||
| except NotImplementedError as e: | |||||
| logger.debug("[WX]single message {} skipped: {}".format(msg["MsgId"], e)) | |||||
| return None | return None | ||||
| WechatChannel().handle_single(WeChatMessage(msg)) | |||||
| WechatChannel().handle_single(cmsg) | |||||
| return None | return None | ||||
| @itchat.msg_register([TEXT, VOICE, PICTURE], isGroupChat=True) | |||||
| @itchat.msg_register([TEXT, VOICE, PICTURE, NOTE], isGroupChat=True) | |||||
| def handler_group_msg(msg): | def handler_group_msg(msg): | ||||
| if msg["Type"] == PICTURE and msg["MsgType"] == 47: | |||||
| try: | |||||
| cmsg = WeChatMessage(msg, True) | |||||
| except NotImplementedError as e: | |||||
| logger.debug("[WX]group message {} skipped: {}".format(msg["MsgId"], e)) | |||||
| return None | return None | ||||
| WechatChannel().handle_group(WeChatMessage(msg, True)) | |||||
| WechatChannel().handle_group(cmsg) | |||||
| return None | return None | ||||
| @@ -165,12 +170,16 @@ class WechatChannel(ChatChannel): | |||||
| logger.debug("[WX]receive voice msg: {}".format(cmsg.content)) | logger.debug("[WX]receive voice msg: {}".format(cmsg.content)) | ||||
| elif cmsg.ctype == ContextType.IMAGE: | elif cmsg.ctype == ContextType.IMAGE: | ||||
| logger.debug("[WX]receive image msg: {}".format(cmsg.content)) | logger.debug("[WX]receive image msg: {}".format(cmsg.content)) | ||||
| else: | |||||
| elif cmsg.ctype == ContextType.PATPAT: | |||||
| logger.debug("[WX]receive patpat msg: {}".format(cmsg.content)) | |||||
| elif cmsg.ctype == ContextType.TEXT: | |||||
| logger.debug( | logger.debug( | ||||
| "[WX]receive text msg: {}, cmsg={}".format( | "[WX]receive text msg: {}, cmsg={}".format( | ||||
| json.dumps(cmsg._rawmsg, ensure_ascii=False), cmsg | json.dumps(cmsg._rawmsg, ensure_ascii=False), cmsg | ||||
| ) | ) | ||||
| ) | ) | ||||
| else: | |||||
| logger.debug("[WX]receive msg: {}, cmsg={}".format(cmsg.content, cmsg)) | |||||
| context = self._compose_context( | context = self._compose_context( | ||||
| cmsg.ctype, cmsg.content, isgroup=False, msg=cmsg | cmsg.ctype, cmsg.content, isgroup=False, msg=cmsg | ||||
| ) | ) | ||||
| @@ -186,9 +195,13 @@ class WechatChannel(ChatChannel): | |||||
| logger.debug("[WX]receive voice for group msg: {}".format(cmsg.content)) | logger.debug("[WX]receive voice for group msg: {}".format(cmsg.content)) | ||||
| elif cmsg.ctype == ContextType.IMAGE: | elif cmsg.ctype == ContextType.IMAGE: | ||||
| logger.debug("[WX]receive image for group msg: {}".format(cmsg.content)) | logger.debug("[WX]receive image for group msg: {}".format(cmsg.content)) | ||||
| else: | |||||
| elif cmsg.ctype in [ContextType.JOIN_GROUP, ContextType.PATPAT]: | |||||
| logger.debug("[WX]receive note msg: {}".format(cmsg.content)) | |||||
| elif cmsg.ctype == ContextType.TEXT: | |||||
| # logger.debug("[WX]receive group msg: {}, cmsg={}".format(json.dumps(cmsg._rawmsg, ensure_ascii=False), cmsg)) | # logger.debug("[WX]receive group msg: {}, cmsg={}".format(json.dumps(cmsg._rawmsg, ensure_ascii=False), cmsg)) | ||||
| pass | pass | ||||
| else: | |||||
| logger.debug("[WX]receive group msg: {}".format(cmsg.content)) | |||||
| context = self._compose_context( | context = self._compose_context( | ||||
| cmsg.ctype, cmsg.content, isgroup=True, msg=cmsg | cmsg.ctype, cmsg.content, isgroup=True, msg=cmsg | ||||
| ) | ) | ||||
+ 33
- 2
channel/wechat/wechat_message.py
Vedi File
| @@ -1,3 +1,5 @@ | |||||
| import re | |||||
| from bridge.context import ContextType | from bridge.context import ContextType | ||||
| from channel.chat_message import ChatMessage | from channel.chat_message import ChatMessage | ||||
| from common.log import logger | from common.log import logger | ||||
| @@ -24,9 +26,37 @@ class WeChatMessage(ChatMessage): | |||||
| self.ctype = ContextType.IMAGE | self.ctype = ContextType.IMAGE | ||||
| self.content = TmpDir().path() + itchat_msg["FileName"] # content直接存临时目录路径 | self.content = TmpDir().path() + itchat_msg["FileName"] # content直接存临时目录路径 | ||||
| self._prepare_fn = lambda: itchat_msg.download(self.content) | self._prepare_fn = lambda: itchat_msg.download(self.content) | ||||
| elif itchat_msg["Type"] == NOTE and itchat_msg["MsgType"] == 10000: | |||||
| if is_group and ( | |||||
| "加入群聊" in itchat_msg["Content"] or "加入了群聊" in itchat_msg["Content"] | |||||
| ): | |||||
| self.ctype = ContextType.JOIN_GROUP | |||||
| self.content = itchat_msg["Content"] | |||||
| # 这里只能得到nickname, actual_user_id还是机器人的id | |||||
| if "加入了群聊" in itchat_msg["Content"]: | |||||
| self.actual_user_nickname = re.findall( | |||||
| r"\"(.*?)\"", itchat_msg["Content"] | |||||
| )[-1] | |||||
| elif "加入群聊" in itchat_msg["Content"]: | |||||
| self.actual_user_nickname = re.findall( | |||||
| r"\"(.*?)\"", itchat_msg["Content"] | |||||
| )[0] | |||||
| elif "拍了拍我" in itchat_msg["Content"]: | |||||
| self.ctype = ContextType.PATPAT | |||||
| self.content = itchat_msg["Content"] | |||||
| if is_group: | |||||
| self.actual_user_nickname = re.findall( | |||||
| r"\"(.*?)\"", itchat_msg["Content"] | |||||
| )[0] | |||||
| else: | |||||
| raise NotImplementedError( | |||||
| "Unsupported note message: " + itchat_msg["Content"] | |||||
| ) | |||||
| else: | else: | ||||
| raise NotImplementedError( | raise NotImplementedError( | ||||
| "Unsupported message type: {}".format(itchat_msg["Type"]) | |||||
| "Unsupported message type: Type:{} MsgType:{}".format( | |||||
| itchat_msg["Type"], itchat_msg["MsgType"] | |||||
| ) | |||||
| ) | ) | ||||
| self.from_user_id = itchat_msg["FromUserName"] | self.from_user_id = itchat_msg["FromUserName"] | ||||
| @@ -58,4 +88,5 @@ class WeChatMessage(ChatMessage): | |||||
| if self.is_group: | if self.is_group: | ||||
| self.is_at = itchat_msg["IsAt"] | self.is_at = itchat_msg["IsAt"] | ||||
| self.actual_user_id = itchat_msg["ActualUserName"] | self.actual_user_id = itchat_msg["ActualUserName"] | ||||
| self.actual_user_nickname = itchat_msg["ActualNickName"] | |||||
| if self.ctype not in [ContextType.JOIN_GROUP, ContextType.PATPAT]: | |||||
| self.actual_user_nickname = itchat_msg["ActualNickName"] | |||||
+ 1
- 1
plugins/banwords/banwords.py
Vedi File
| @@ -102,4 +102,4 @@ class Banwords(Plugin): | |||||
| return | return | ||||
| def get_help_text(self, **kwargs): | def get_help_text(self, **kwargs): | ||||
| return Banwords.desc | |||||
| return "过滤消息中的敏感词。" | |||||
+ 21
- 1
plugins/hello/hello.py
Vedi File
| @@ -23,7 +23,27 @@ class Hello(Plugin): | |||||
| logger.info("[Hello] inited") | logger.info("[Hello] inited") | ||||
| def on_handle_context(self, e_context: EventContext): | def on_handle_context(self, e_context: EventContext): | ||||
| if e_context["context"].type != ContextType.TEXT: | |||||
| if e_context["context"].type not in [ | |||||
| ContextType.TEXT, | |||||
| ContextType.JOIN_GROUP, | |||||
| ContextType.PATPAT, | |||||
| ]: | |||||
| return | |||||
| if e_context["context"].type == ContextType.JOIN_GROUP: | |||||
| e_context["context"].type = ContextType.TEXT | |||||
| msg: ChatMessage = e_context["context"]["msg"] | |||||
| e_context[ | |||||
| "context" | |||||
| ].content = f'请你随机使用一种风格说一句问候语来欢迎新用户"{msg.actual_user_nickname}"加入群聊。' | |||||
| e_context.action = EventAction.CONTINUE # 事件继续,交付给下个插件或默认逻辑 | |||||
| return | |||||
| if e_context["context"].type == ContextType.PATPAT: | |||||
| e_context["context"].type = ContextType.TEXT | |||||
| msg: ChatMessage = e_context["context"]["msg"] | |||||
| e_context["context"].content = f"请你随机使用一种风格介绍你自己,并告诉用户输入#help可以查看帮助信息。" | |||||
| e_context.action = EventAction.CONTINUE # 事件继续,交付给下个插件或默认逻辑 | |||||
| return | return | ||||
| content = e_context["context"].content | content = e_context["context"].content | ||||
+ 13
- 0
plugins/keyword/README.md
Vedi File
| @@ -0,0 +1,13 @@ | |||||
| # 目的 | |||||
| 关键字匹配并回复 | |||||
| # 试用场景 | |||||
| 目前是在微信公众号下面使用过。 | |||||
| # 使用步骤 | |||||
| 1. 复制 `config.json.template` 为 `config.json` | |||||
| 2. 在关键字 `keyword` 新增需要关键字匹配的内容 | |||||
| 3. 重启程序做验证 | |||||
| # 验证结果 | |||||
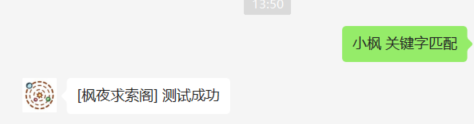
|  | |||||
+ 1
- 0
plugins/keyword/__init__.py
Vedi File
| @@ -0,0 +1 @@ | |||||
| from .keyword import * | |||||
+ 5
- 0
plugins/keyword/config.json.template
Vedi File
| @@ -0,0 +1,5 @@ | |||||
| { | |||||
| "keyword": { | |||||
| "关键字匹配": "测试成功" | |||||
| } | |||||
| } | |||||
+ 67
- 0
plugins/keyword/keyword.py
Vedi File
| @@ -0,0 +1,67 @@ | |||||
| # encoding:utf-8 | |||||
| import json | |||||
| import os | |||||
| import plugins | |||||
| from bridge.context import ContextType | |||||
| from bridge.reply import Reply, ReplyType | |||||
| from common.log import logger | |||||
| from plugins import * | |||||
| @plugins.register( | |||||
| name="Keyword", | |||||
| desire_priority=900, | |||||
| hidden=True, | |||||
| desc="关键词匹配过滤", | |||||
| version="0.1", | |||||
| author="fengyege.top", | |||||
| ) | |||||
| class Keyword(Plugin): | |||||
| def __init__(self): | |||||
| super().__init__() | |||||
| try: | |||||
| curdir = os.path.dirname(__file__) | |||||
| config_path = os.path.join(curdir, "config.json") | |||||
| conf = None | |||||
| if not os.path.exists(config_path): | |||||
| logger.debug(f"[keyword]不存在配置文件{config_path}") | |||||
| conf = {"keyword": {}} | |||||
| with open(config_path, "w", encoding="utf-8") as f: | |||||
| json.dump(conf, f, indent=4) | |||||
| else: | |||||
| logger.debug(f"[keyword]加载配置文件{config_path}") | |||||
| with open(config_path, "r", encoding="utf-8") as f: | |||||
| conf = json.load(f) | |||||
| # 加载关键词 | |||||
| self.keyword = conf["keyword"] | |||||
| logger.info("[keyword] {}".format(self.keyword)) | |||||
| self.handlers[Event.ON_HANDLE_CONTEXT] = self.on_handle_context | |||||
| logger.info("[keyword] inited.") | |||||
| except Exception as e: | |||||
| logger.warn( | |||||
| "[keyword] init failed, ignore or see https://github.com/zhayujie/chatgpt-on-wechat/tree/master/plugins/keyword ." | |||||
| ) | |||||
| raise e | |||||
| def on_handle_context(self, e_context: EventContext): | |||||
| if e_context["context"].type != ContextType.TEXT: | |||||
| return | |||||
| content = e_context["context"].content.strip() | |||||
| logger.debug("[keyword] on_handle_context. content: %s" % content) | |||||
| if content in self.keyword: | |||||
| logger.debug(f"[keyword] 匹配到关键字【{content}】") | |||||
| reply_text = self.keyword[content] | |||||
| reply = Reply() | |||||
| reply.type = ReplyType.TEXT | |||||
| reply.content = reply_text | |||||
| e_context["reply"] = reply | |||||
| e_context.action = EventAction.BREAK_PASS # 事件结束,并跳过处理context的默认逻辑 | |||||
| def get_help_text(self, **kwargs): | |||||
| help_text = "关键词过滤" | |||||
| return help_text | |||||
BIN
plugins/keyword/test-keyword.png
Vedi File
{kind=link}
| Before | After |
|---|---|
|
|
| Width: 474 | Height: 124 | Size: 12KB |
+ 59
- 11
plugins/tool/README.md
Vedi File
| @@ -9,9 +9,21 @@ | |||||
| ### 1. python | ### 1. python | ||||
| ###### python解释器,使用它来解释执行python指令,可以配合你想要chatgpt生成的代码输出结果或执行事务 | ###### python解释器,使用它来解释执行python指令,可以配合你想要chatgpt生成的代码输出结果或执行事务 | ||||
| ### 2. url-get | |||||
| ### 2. 访问网页的工具汇总(默认url-get) | |||||
| #### 2.1 url-get | |||||
| ###### 往往用来获取某个网站具体内容,结果可能会被反爬策略影响 | ###### 往往用来获取某个网站具体内容,结果可能会被反爬策略影响 | ||||
| #### 2.2 browser | |||||
| ###### 浏览器,功能与2.1类似,但能更好模拟,不会被识别为爬虫影响获取网站内容 | |||||
| > 注1:url-get默认配置、browser需额外配置,browser依赖google-chrome,你需要提前安装好 | |||||
| > 注2:browser默认使用summary tool 分段总结长文本信息,tokens可能会大量消耗! | |||||
| 这是debian端安装google-chrome教程,其他系统请执行查找 | |||||
| > https://www.linuxjournal.com/content/how-can-you-install-google-browser-debian | |||||
| ### 3. terminal | ### 3. terminal | ||||
| ###### 在你运行的电脑里执行shell命令,可以配合你想要chatgpt生成的代码使用,给予自然语言控制手段 | ###### 在你运行的电脑里执行shell命令,可以配合你想要chatgpt生成的代码使用,给予自然语言控制手段 | ||||
| @@ -38,47 +50,83 @@ | |||||
| ### 5. wikipedia | ### 5. wikipedia | ||||
| ###### 可以回答你想要知道确切的人事物 | ###### 可以回答你想要知道确切的人事物 | ||||
| ### 6. news * | |||||
| ### 6. 新闻类工具 | |||||
| #### 6.1. news-api * | |||||
| ###### 从全球 80,000 多个信息源中获取当前和历史新闻文章 | ###### 从全球 80,000 多个信息源中获取当前和历史新闻文章 | ||||
| ### 7. morning-news * | |||||
| #### 6.2. morning-news * | |||||
| ###### 每日60秒早报,每天凌晨一点更新,本工具使用了[alapi-每日60秒早报](https://alapi.cn/api/view/93) | ###### 每日60秒早报,每天凌晨一点更新,本工具使用了[alapi-每日60秒早报](https://alapi.cn/api/view/93) | ||||
| > 该tool每天返回内容相同 | > 该tool每天返回内容相同 | ||||
| ### 8. bing-search * | |||||
| #### 6.3. finance-news | |||||
| ###### 获取实时的金融财政新闻 | |||||
| > 该工具需要解决browser tool 的google-chrome依赖安装 | |||||
| ### 7. bing-search * | |||||
| ###### bing搜索引擎,从此你不用再烦恼搜索要用哪些关键词 | ###### bing搜索引擎,从此你不用再烦恼搜索要用哪些关键词 | ||||
| ### 9. wolfram-alpha * | |||||
| ### 8. wolfram-alpha * | |||||
| ###### 知识搜索引擎、科学问答系统,常用于专业学科计算 | ###### 知识搜索引擎、科学问答系统,常用于专业学科计算 | ||||
| ### 10. google-search * | |||||
| ### 9. google-search * | |||||
| ###### google搜索引擎,申请流程较bing-search繁琐 | ###### google搜索引擎,申请流程较bing-search繁琐 | ||||
| ###### 注1:带*工具需要获取api-key才能使用,部分工具需要外网支持 | |||||
| ### 10. arxiv(dev 开发中) | |||||
| ###### 用于查找论文 | |||||
| ### 11. debug(dev 开发中,目前没有接入wechat) | |||||
| ###### 当bot遇到无法确定的信息时,将会向你寻求帮助的工具 | |||||
| ### 12. summary | |||||
| ###### 总结工具,该工具必须输入一个本地文件的绝对路径 | |||||
| > 该工具目前是和其他工具配合使用,暂未测试单独使用效果 | |||||
| ### 13. image2text | |||||
| ###### 将图片转换成文字,底层调用imageCaption模型,该工具必须输入一个本地文件的绝对路径 | |||||
| ### 14. searxng-search * | |||||
| ###### 一个私有化的搜索引擎工具 | |||||
| > 安装教程:https://docs.searxng.org/admin/installation.html | |||||
| --- | |||||
| ###### 注1:带*工具需要获取api-key才能使用(在config.json内的kwargs添加项),部分工具需要外网支持 | |||||
| #### [申请方法](https://github.com/goldfishh/chatgpt-tool-hub/blob/master/docs/apply_optional_tool.md) | #### [申请方法](https://github.com/goldfishh/chatgpt-tool-hub/blob/master/docs/apply_optional_tool.md) | ||||
| ## config.json 配置说明 | ## config.json 配置说明 | ||||
| ###### 默认工具无需配置,其它工具需手动配置,一个例子: | ###### 默认工具无需配置,其它工具需手动配置,一个例子: | ||||
| ```json | ```json | ||||
| { | { | ||||
| "tools": ["wikipedia"], // 填入你想用到的额外工具名 | |||||
| "tools": ["wikipedia", "你想要添加的其他工具"], // 填入你想用到的额外工具名 | |||||
| "kwargs": { | "kwargs": { | ||||
| "request_timeout": 60, // openai接口超时时间 | |||||
| "debug": true, // 当你遇到问题求助时,需要配置 | |||||
| "request_timeout": 120, // openai接口超时时间 | |||||
| "no_default": false, // 是否不使用默认的4个工具 | "no_default": false, // 是否不使用默认的4个工具 | ||||
| "OPTIONAL_API_NAME": "OPTIONAL_API_KEY" // 带*工具需要申请api-key,在这里填入,api_name参考前述`申请方法` | |||||
| // 带*工具需要申请api-key,在这里填入,api_name参考前述`申请方法` | |||||
| } | } | ||||
| } | } | ||||
| ``` | ``` | ||||
| 注:config.json文件非必须,未创建仍可使用本tool;带*工具需在kwargs填入对应api-key键值对 | 注:config.json文件非必须,未创建仍可使用本tool;带*工具需在kwargs填入对应api-key键值对 | ||||
| - `tools`:本插件初始化时加载的工具, 目前可选集:["wikipedia", "wolfram-alpha", "bing-search", "google-search", "news", "morning-news"] & 默认工具,除wikipedia工具之外均需要申请api-key | |||||
| - `tools`:本插件初始化时加载的工具, 目前可选集:["wikipedia", "wolfram-alpha", "bing-search", "google-search", "news"] & 默认工具,除wikipedia工具之外均需要申请api-key | |||||
| - `kwargs`:工具执行时的配置,一般在这里存放**api-key**,或环境配置 | - `kwargs`:工具执行时的配置,一般在这里存放**api-key**,或环境配置 | ||||
| - `debug`: 输出chatgpt-tool-hub额外信息用于调试 | |||||
| - `request_timeout`: 访问openai接口的超时时间,默认与wechat-on-chatgpt配置一致,可单独配置 | - `request_timeout`: 访问openai接口的超时时间,默认与wechat-on-chatgpt配置一致,可单独配置 | ||||
| - `no_default`: 用于配置默认加载4个工具的行为,如果为true则仅使用tools列表工具,不加载默认工具 | - `no_default`: 用于配置默认加载4个工具的行为,如果为true则仅使用tools列表工具,不加载默认工具 | ||||
| - `top_k_results`: 控制所有有关搜索的工具返回条目数,数字越高则参考信息越多,但无用信息可能干扰判断,该值一般为2 | - `top_k_results`: 控制所有有关搜索的工具返回条目数,数字越高则参考信息越多,但无用信息可能干扰判断,该值一般为2 | ||||
| - `model_name`: 用于控制tool插件底层使用的llm模型,目前暂未测试3.5以外的模型,一般保持默认 | - `model_name`: 用于控制tool插件底层使用的llm模型,目前暂未测试3.5以外的模型,一般保持默认 | ||||
| --- | |||||
| ## 备注 | ## 备注 | ||||
| - 强烈建议申请搜索工具搭配使用,推荐bing-search | - 强烈建议申请搜索工具搭配使用,推荐bing-search | ||||
+ 12
- 13
plugins/tool/tool.py
Vedi File
| @@ -1,7 +1,7 @@ | |||||
| import json | import json | ||||
| import os | import os | ||||
| from chatgpt_tool_hub.apps import load_app | |||||
| from chatgpt_tool_hub.apps import AppFactory | |||||
| from chatgpt_tool_hub.apps.app import App | from chatgpt_tool_hub.apps.app import App | ||||
| from chatgpt_tool_hub.tools.all_tool_list import get_all_tool_names | from chatgpt_tool_hub.tools.all_tool_list import get_all_tool_names | ||||
| @@ -18,7 +18,7 @@ from plugins import * | |||||
| @plugins.register( | @plugins.register( | ||||
| name="tool", | name="tool", | ||||
| desc="Arming your ChatGPT bot with various tools", | desc="Arming your ChatGPT bot with various tools", | ||||
| version="0.3", | |||||
| version="0.4", | |||||
| author="goldfishh", | author="goldfishh", | ||||
| desire_priority=0, | desire_priority=0, | ||||
| ) | ) | ||||
| @@ -131,17 +131,17 @@ class Tool(Plugin): | |||||
| def _build_tool_kwargs(self, kwargs: dict): | def _build_tool_kwargs(self, kwargs: dict): | ||||
| tool_model_name = kwargs.get("model_name") | tool_model_name = kwargs.get("model_name") | ||||
| request_timeout = kwargs.get("request_timeout") | |||||
| return { | return { | ||||
| "debug": kwargs.get("debug", False), | |||||
| "openai_api_key": conf().get("open_ai_api_key", ""), | "openai_api_key": conf().get("open_ai_api_key", ""), | ||||
| "proxy": conf().get("proxy", ""), | "proxy": conf().get("proxy", ""), | ||||
| "request_timeout": str(conf().get("request_timeout", 60)), | |||||
| "request_timeout": request_timeout if request_timeout else conf().get("request_timeout", 120), | |||||
| # note: 目前tool暂未对其他模型测试,但这里仍对配置来源做了优先级区分,一般插件配置可覆盖全局配置 | # note: 目前tool暂未对其他模型测试,但这里仍对配置来源做了优先级区分,一般插件配置可覆盖全局配置 | ||||
| "model_name": tool_model_name | |||||
| if tool_model_name | |||||
| else conf().get("model", "gpt-3.5-turbo"), | |||||
| "model_name": tool_model_name if tool_model_name else conf().get("model", "gpt-3.5-turbo"), | |||||
| "no_default": kwargs.get("no_default", False), | "no_default": kwargs.get("no_default", False), | ||||
| "top_k_results": kwargs.get("top_k_results", 2), | |||||
| "top_k_results": kwargs.get("top_k_results", 3), | |||||
| # for news tool | # for news tool | ||||
| "news_api_key": kwargs.get("news_api_key", ""), | "news_api_key": kwargs.get("news_api_key", ""), | ||||
| # for bing-search tool | # for bing-search tool | ||||
| @@ -157,8 +157,6 @@ class Tool(Plugin): | |||||
| "zaobao_api_key": kwargs.get("zaobao_api_key", ""), | "zaobao_api_key": kwargs.get("zaobao_api_key", ""), | ||||
| # for visual_dl tool | # for visual_dl tool | ||||
| "cuda_device": kwargs.get("cuda_device", "cpu"), | "cuda_device": kwargs.get("cuda_device", "cpu"), | ||||
| # for browser tool | |||||
| "phantomjs_exec_path": kwargs.get("phantomjs_exec_path", ""), | |||||
| } | } | ||||
| def _filter_tool_list(self, tool_list: list): | def _filter_tool_list(self, tool_list: list): | ||||
| @@ -172,11 +170,12 @@ class Tool(Plugin): | |||||
| def _reset_app(self) -> App: | def _reset_app(self) -> App: | ||||
| tool_config = self._read_json() | tool_config = self._read_json() | ||||
| app_kwargs = self._build_tool_kwargs(tool_config.get("kwargs", {})) | |||||
| app = AppFactory() | |||||
| app.init_env(**app_kwargs) | |||||
| # filter not support tool | # filter not support tool | ||||
| tool_list = self._filter_tool_list(tool_config.get("tools", [])) | tool_list = self._filter_tool_list(tool_config.get("tools", [])) | ||||
| return load_app( | |||||
| tools_list=tool_list, | |||||
| **self._build_tool_kwargs(tool_config.get("kwargs", {})), | |||||
| ) | |||||
| return app.create_app(tools_list=tool_list, **app_kwargs) | |||||
+ 2
- 1
requirements-optional.txt
Vedi File
| @@ -20,5 +20,6 @@ pysilk_mod>=1.6.0 # needed by send voice | |||||
| web.py | web.py | ||||
| # chatgpt-tool-hub plugin | # chatgpt-tool-hub plugin | ||||
| --extra-index-url https://pypi.python.org/simple | --extra-index-url https://pypi.python.org/simple | ||||
| chatgpt_tool_hub>=0.3.9 | |||||
| chatgpt_tool_hub>=0.4.1 | |||||
+ 10
- 2
voice/azure/azure_voice.py
Vedi File
| @@ -66,7 +66,11 @@ class AzureVoice(Voice): | |||||
| ) | ) | ||||
| reply = Reply(ReplyType.TEXT, result.text) | reply = Reply(ReplyType.TEXT, result.text) | ||||
| else: | else: | ||||
| logger.error("[Azure] voiceToText error, result={}".format(result)) | |||||
| logger.error( | |||||
| "[Azure] voiceToText error, result={}, canceldetails={}".format( | |||||
| result, result.cancellation_details | |||||
| ) | |||||
| ) | |||||
| reply = Reply(ReplyType.ERROR, "抱歉,语音识别失败") | reply = Reply(ReplyType.ERROR, "抱歉,语音识别失败") | ||||
| return reply | return reply | ||||
| @@ -83,6 +87,10 @@ class AzureVoice(Voice): | |||||
| ) | ) | ||||
| reply = Reply(ReplyType.VOICE, fileName) | reply = Reply(ReplyType.VOICE, fileName) | ||||
| else: | else: | ||||
| logger.error("[Azure] textToVoice error, result={}".format(result)) | |||||
| logger.error( | |||||
| "[Azure] textToVoice error, result={}, canceldetails={}".format( | |||||
| result, result.cancellation_details | |||||
| ) | |||||
| ) | |||||
| reply = Reply(ReplyType.ERROR, "抱歉,语音合成失败") | reply = Reply(ReplyType.ERROR, "抱歉,语音合成失败") | ||||
| return reply | return reply | ||||
Loading…